Токены в нейросетях. Что это и откуда берётся?
В данной статье мы разберём как нейросеть видит текст, который мы ей отправили, познакомимся очень близко с термином ТОКЕНЫ, и даже сами создадим те самые токены на Python.
Поехали
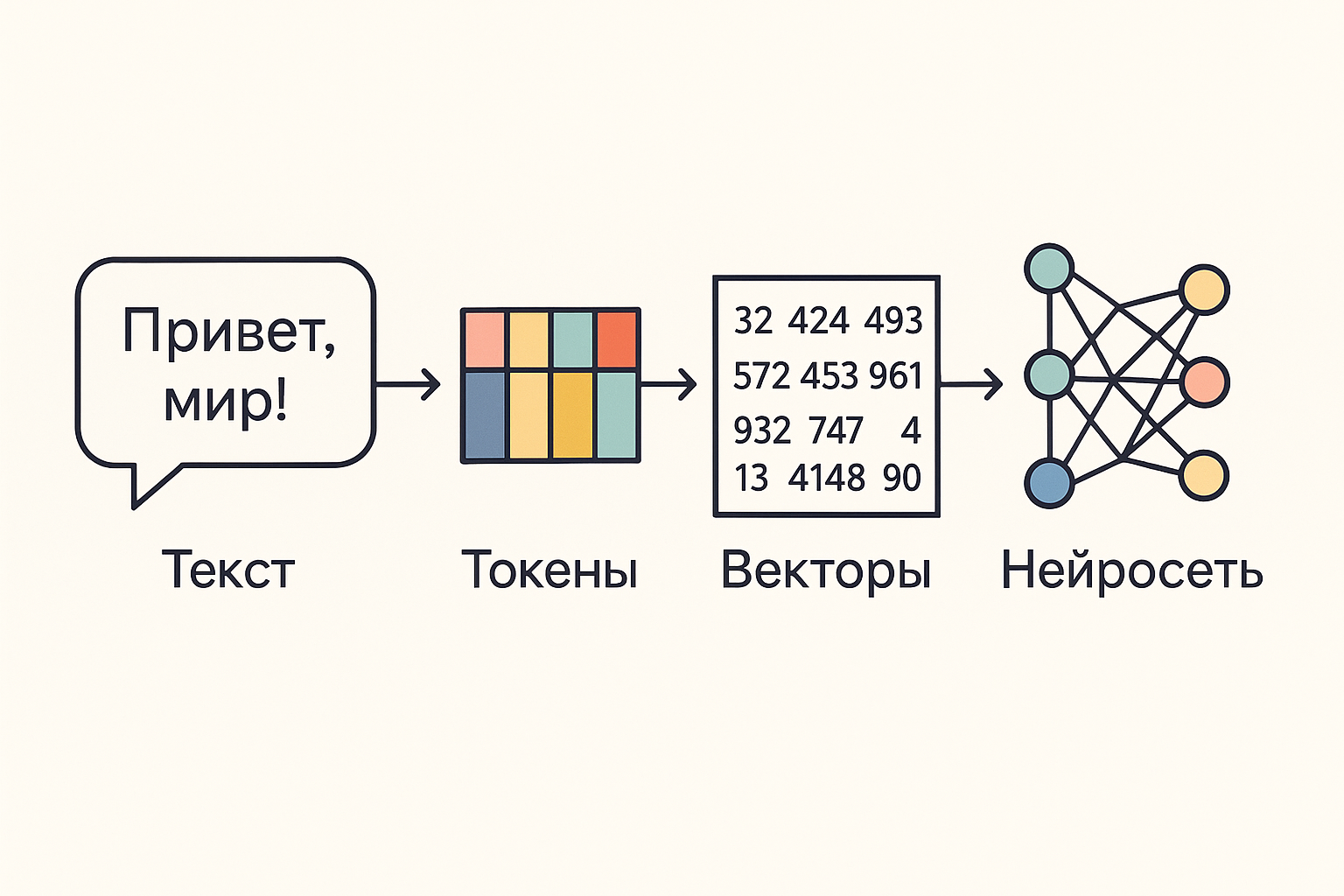
Для начала, давайте в общих чертах посмотрим на весь путь текста от Юзера до Нейросети.
А теперь в обратном порядке, для более логичного пути от причины к следствию.
Так как нейросеть - это очень сложный математический алгоритм, на вход он должен принимать понятные математические единицы, в текстовых нейросетях, это Векторы.
Вектор — это математический объект: упорядоченный набор чисел (координат).
Пример: [1.2, -0.3, 0.7, ...].
Если совсем упрощать, это как путь по карте (1.2 шага влево, 0.3 шага назад, копать на 0.7 метра вниз)
Векторы, мы в свою очередь получаем из словаря токенов, который мы создаём даже раньше, чем саму Нейросеть.
Ниже, мы как раз и будем создавать такой словарь сами с нуля!
Словарь токенов - это словарь, где у нас лежит набор заранее полученных токенов и каждому Токену соответствует свой Вектор.
Это можно сравнить со словарём иностранного языка.
Что такое токен?
Токеном может быть совокупность одного и более символов.
Для нас, людей, часто токены не будут нести смысл.
Но чем более большой датасет(набор данных для обучения), тем больше токены будут похожи на слова.
Пример мы рассмотрим ниже.
Итого, мы прошли по пути:
Текст -> Токены -> Вектора -> Нейросеть
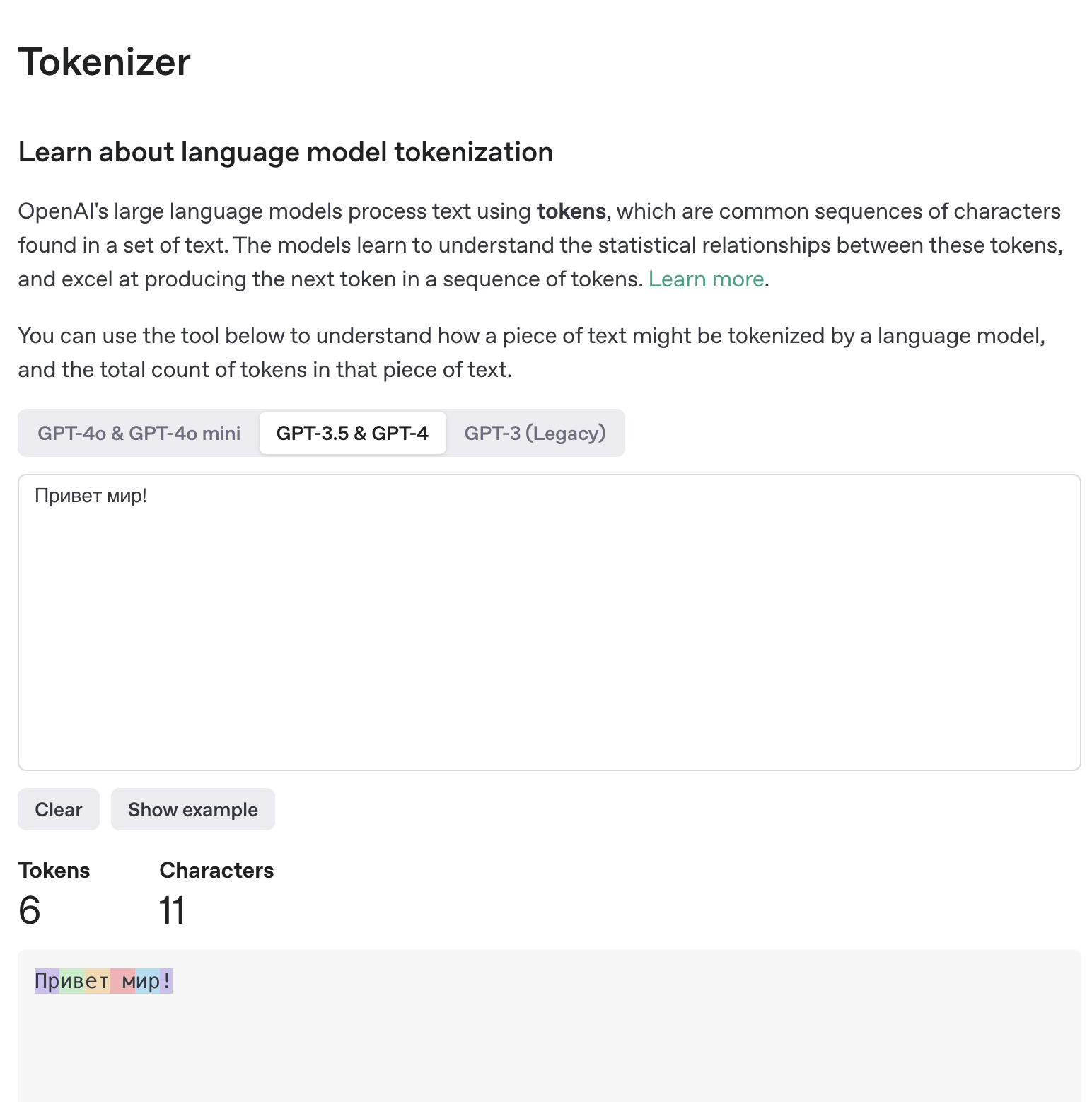
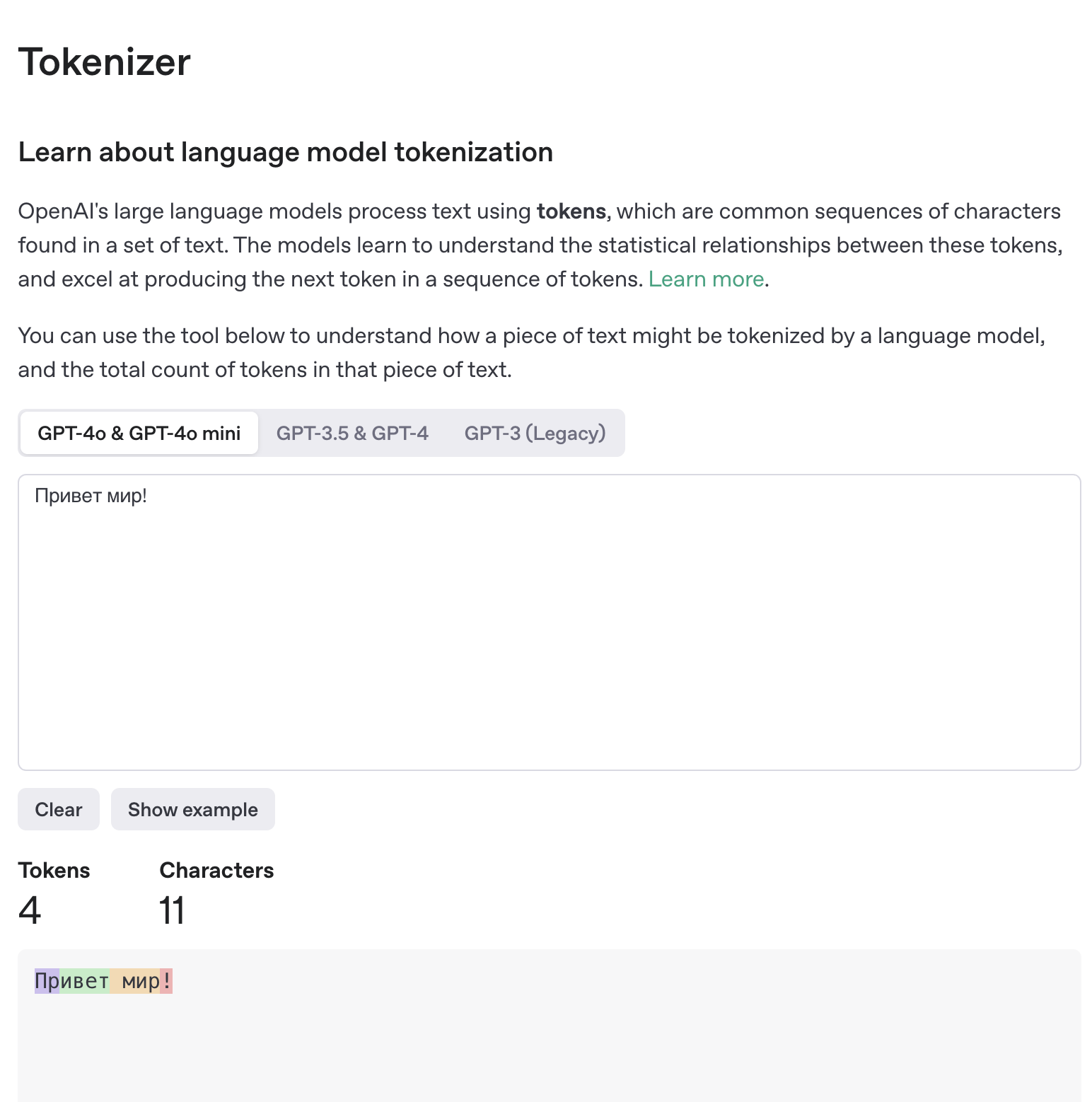
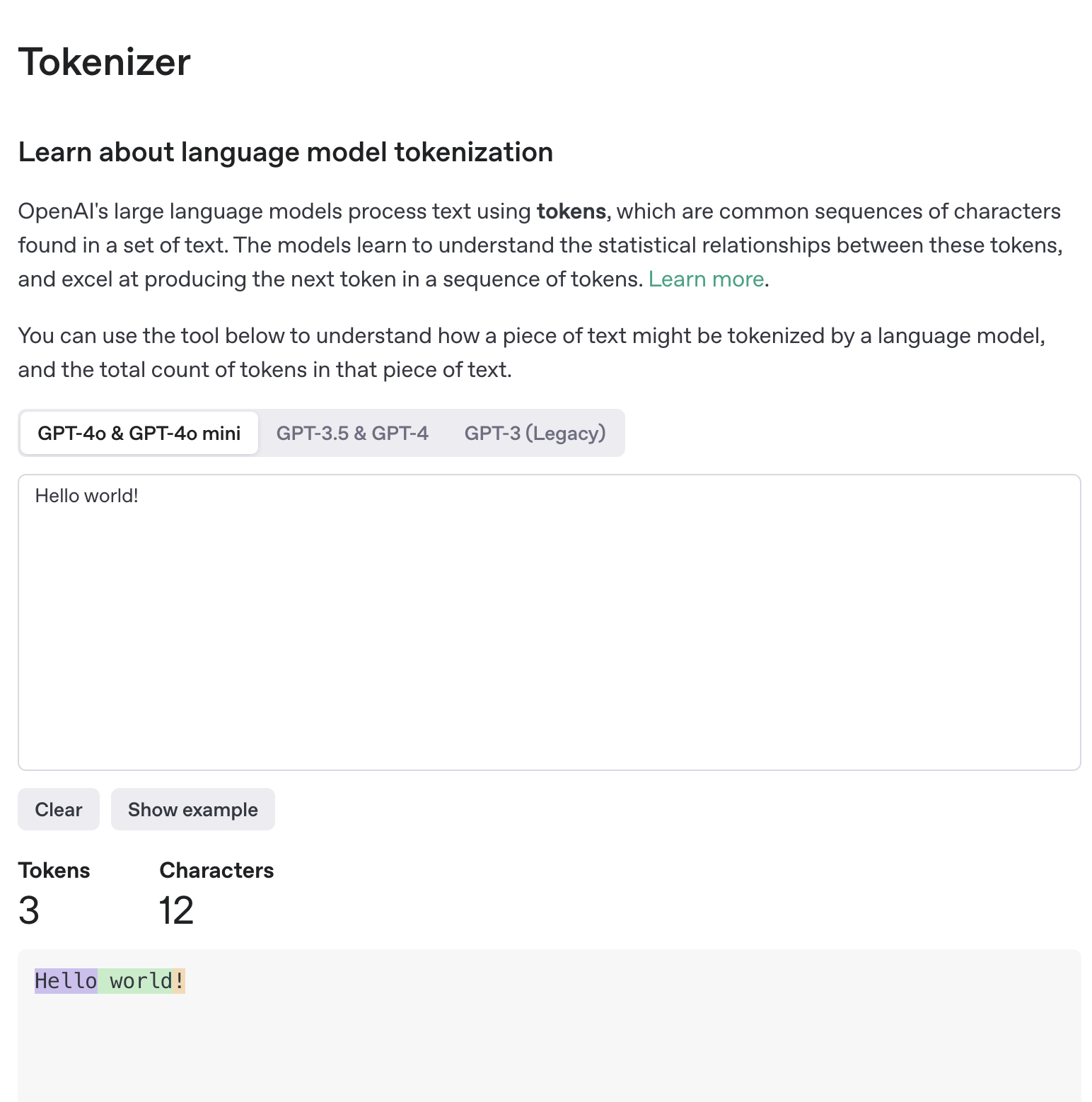
"Привет мир!" -> "Привет", "мир", "!" -> [1.2, -0.3, 0.7, ...], [-0.1, 1.3, -7.7, ...], [9.2, -4.1, 7.7, ...] -> Нейросеть
В общих чертах теперь понятно, что из себя представляет каждый этап.
Переходим от общего к конкретике.
Словарь токенов - это набор от одного или более символов, чаще всего попадающиеся нам в наборе данных, который мы взяли за основу составления словаря.
Обычно, для больших языковых моделей, это терабайты текста (триллионы символов).
И чтобы создать такой словарь у нас есть разные алгоритмы, о которых мы поговорим позже, но их суть одна. Найти самые частые по встречаемости символы или наборы символов в датасете (тот самый набор данных) и создать из них токены.
Тем самым Токен - это то, что было найдено в тексте чаще остальных сочетаний символов, и было вынесено в отдельной единицей в словарь.
Токены в процессе обучения формируются постепенно в тысячи или миллионы операций.
Для этого изначально вообще весь датасет разбивается посимвольно, после чего мы начинаем склеивать рядом стоящие символы и считать, каких сочетаний было найдено больше всего. Какое сочетание было найдено в датасете больше всего раз, то сочетание мы и выносим в наш словарь токенов, тем самым пополняя его новыми токенами.
Давайте создадим свой словарь токенов на основе 2 строк текста в качестве примера:
Предложения:
- привет мир
- ветхий дом
Для начала заменим символы (не буквы) на _ .
Теперь по шагам прогоним наши строки, чтобы получить словарь
| Шаг |
Текущая разбивка |
Самая частая пара |
Что добавляем |
Почему именно она |
| 0 |
▁ п р и в е т ▁ м и р ▁ в е т х и й ▁ д о м |
— |
— |
Стартуем с одиночных символов |
| 1 |
▁ п р и ве т ▁ м и р ▁ ве т х и й ▁ д о м |
(в,е) = 2 |
ве |
«ве» встретилось 2 раза (в «привет», «ветхий») — чаще любой другой пары |
| 2 |
▁ п р и вет ▁ м и р ▁ вет х и й ▁ д о м |
(ве,т) = 2 |
вет |
После первого слияния пара «вет» стала самой частой |
| 3 |
▁ привет ▁ м и р ▁ вет х и й ▁ д о м |
— |
— |
Пара «пр…» встречается только раз, поэтому дальнейшие слияния смысл не дают при таком крохотном наборе |
Что видно
- Каждую итерацию считаем частоты соседних токенов.
- Склеиваем самую частую пару → уточняем разбиение → повторяем.
- Благодаря повтору «вет» сразу из двух слов токен вет быстро попал в словарь.
На реальных данных объём больше и шагов больше, но логика та же.
Ниже мы посмотрим на реальных примерах.
Субслова — это кусочки слова, которые меньше целого слова, но больше отдельного символа.
Нужны, чтобы модель могла:
- Собирать редкие слова из известных частей:
электро + скутер → «электроскутер».
- Не раздувать словарь до миллионов словоформ.
Типичный пример разбиения по BPE:
непредсказуемый → непред + сказуем + ый
Так модель знает корень «сказ», суффикс «-уем-», окончание «-ый» и может понять / сгенерировать множество похожих слов, даже если целое слово не встречалось в обучении.
Алгоритмы субворд‑токенизации
Самые распространённые — BPE, WordPiece и SentencePiece. Они работают примерно по одному принципу: строят словарь субслов, начиная с символов, и постепенно объединяют наиболее частые сочетания.
🔹 BPE (Byte‑Pair Encoding)
- Берут набор символов (включая пробелы и байты).
- Считают все пары символов/субслов и находят самую частую.
- Объединяют её в единый токен и добавляют в словарь.
- Повторяют, пока не достигнут нужного размера словаря.
Преимущество: обрабатывает редко встречающиеся слова, разбивая их на части. Byte‑level BPE сначала переводит текст в UTF‑8 байты, чтобы покрыть любые символы.
🔹 WordPiece
Похож на BPE, но объединяет пары не просто по частоте, а по тому, насколько сильно увеличится вероятность текстов при добавлении этой пары, то есть делает merge по критерию максимального правдоподобия. Используется, например, в BERT.
🔹 SentencePiece
Это обёртка, которая может использовать BPE или Unigram LM без явной предобработки (работает прямо с "сырым" текстом, включая пробелы). Очень подходит для языков без разделения слов пробелами.
Кстати, пример в таблице выше использовал алгоритм BPE.
КОД
Теорию потрогали.
Давайте перейдём к практике.
Создадим свой словарь токенов.
Пойдём по хардкору и будем создавать словарь на чистом Python.
"""
Byte-Pair Encoding (BPE) — учебная реализация на Python
-------------------------------------------------------------
Цель: показать, как из текста автоматически строится словарь субслов.
Алгоритм на каждом шаге ищет самую частую соседнюю пару токенов и склеивает её,
добавляя новый токен в словарь.
"""
from collections import Counter # Counter удобно считать частоты элементов
# Маркер конца слова: нужен, чтобы конец слова не сливался с началом следующего.
# Выбран таким, чтобы в тексте подобного не было
END = ""
def merge_word(tokens, pair, merged_token):
"""
Получает список токенов одного слова и склеивает в нём указанную пару.
tokens : ['м', 'а', 'м', 'а', '']
pair : ('м', 'а')
merged_token : 'ма'
Вернёт: ['ма', 'ма', '']
"""
i, output = 0, []
while i < len(tokens):
# Если стоящие рядом токены образуют нужную пару — склеиваем
if i < len(tokens) - 1 and (tokens[i], tokens[i + 1]) == pair:
output.append(merged_token) # вместо двух токенов кладём один
i += 2 # пропускаем оба
else:
output.append(tokens[i]) # иначе оставляем как есть
i += 1
return output
def bpe_train(corpus: str, num_merges: int = 100):
"""
Строит словарь BPE по заданному тексту.
corpus : сырой текст (строка) — «мама мыла раму»
num_merges : сколько раз выполнять слияния соседних пар
Возвращает set со всеми токенами, включая новые субслова.
"""
# 1. Базовая токенизация: каждое слово → список символов + END-маркер.
# «мама» → [['м', 'а', 'м', 'а', '']]
# «мама мыла раму» → [['м', 'а', 'м', 'а', ''], ['м', 'ы', 'л', 'а', ''], ['р', 'а', 'м', 'у', '']]
tokenized = [list(word) + [END] for word in corpus.strip().split()]
# 2. Начальный словарь — просто множество всех отдельных символов + END.
# {'р', 'м', 'у', 'л', 'а', '', 'ы'}
vocab = set(t for word in tokenized for t in word)
# 3. Пытаемся создать новый токен num_merges раз.
for _ in range(num_merges):
# 3.1 Подсчитываем частоты всех соседних пар токенов во всём корпусе.
# Берём 2 соседних токена (изначально это просто символы) в каждом слове, соединяем.
# Пример первой проходки:
# Первое слово:
# word = ['м', 'а', 'м', 'а', '']
# list(zip(word, word[1:])) = [('м', 'а'), ('а', 'м'), ('м', 'а'), ('а', '')]
# После первой проходки из всех слов получим:
# pairs = Counter({('м', 'а'): 2, ('а', 'м'): 2, ('а', ''): 2, ('м', 'ы'): 1, ('ы', 'л'): 1, ('л', 'а'): 1, ('р', 'а'): 1, ('м', 'у'): 1, ('у', ''): 1})
# Мы видим, что ('м', 'а') идёт первым и встречается 2 раза
pairs = Counter()
for word in tokenized:
pairs.update(zip(word, word[1:]))
# 3.2 Если пар больше нет (все слова длиной 1) — выходим досрочно
# Это происходит, когда КАЖДОЕ слово в переданном тексте стало целым токеном
if not pairs:
break
# 3.3 Берём самую частую пару. Counter.most_common(1)[0] → (пара, частота)
# В первой проходке это ('м', 'а')
best_pair, best_freq = pairs.most_common(1)[0]
# 3.4 Создаём новый токен, склеив два старых («м» + «а» → «ма»)
merged_token = "".join(best_pair)
vocab.add(merged_token) # кладём в словарь токенов
# 3.5 Проходим по каждому слову и склеиваем найденную пару.
# В первой проходке:
# [['м', 'а', 'м', 'а', ''], ['м', 'ы', 'л', 'а', ''], ['р', 'а', 'м', 'у', '']] →→→→ [['ма', 'ма', ''], ['м', 'ы', 'л', 'а', ''], ['р', 'а', 'м', 'у', '']]
tokenized = [
merge_word(word, best_pair, merged_token)
for word in tokenized
]
# Давайте рассмотрим, как будет выглядеть наша переменная tokenized в каждом проходе
# [['ма', 'ма', ''], ['м', 'ы', 'л', 'а', ''], ['р', 'а', 'м', 'у', '']]
# [['мама', ''], ['м', 'ы', 'л', 'а', ''], ['р', 'а', 'м', 'у', '']]
# [['мама'], ['м', 'ы', 'л', 'а', ''], ['р', 'а', 'м', 'у', '']]
# [['мама'], ['мы', 'л', 'а', ''], ['р', 'а', 'м', 'у', '']]
# [['мама'], ['мыл', 'а', ''], ['р', 'а', 'м', 'у', '']]
# [['мама'], ['мыла', ''], ['р', 'а', 'м', 'у', '']]
# [['мама'], ['мыла'], ['р', 'а', 'м', 'у', '']]
# [['мама'], ['мыла'], ['ра', 'м', 'у', '']]
# [['мама'], ['мыла'], ['рам', 'у', '']]
# [['мама'], ['мыла'], ['раму', '']]
# [['мама'], ['мыла'], ['раму']]
# Из-за того, что у нас всего одна одинаковая пара, мы будем склеивать после "ма" токены друг с другом по порядку.
# На данном примере видно, как постепенно токены склеиваются, пока мы не получим из каждого слова токен.
# Если же мы будем брать более большие тексты, а не 3 слова, то будем находить за один проход не по 1 или 2 схожих токена, типа "ма", а сразу по 1000 или 100 000, а это совсем другие масштабы.
# И когда текста так много, то чтобы получить токен равный слову, понадобится невероятно много раз обработать наш текст!
# А это занимает много времени!!!
return vocab
# ------------------------------------------------------------
# Демонстрация
# ------------------------------------------------------------
if __name__ == "__main__":
sample_text = "мама мыла раму"
dictionary = bpe_train(sample_text, num_merges=10)
# Выводим словарь токенов отсортированным для наглядности
print(sorted(dictionary))
Я постарался как можно подробнее прокомментировать код, чтобы было понятно что и где происходит.
По итогу, мы получаем словарь токенов, где каждый токен, это целое слово.
Но добиться "слово = токен" у нас получилось только из-за крайне маленького объёма данных.
А давайте попробуем провернуть то же самое, только теперь мы подключим сюда файл с большим объёмом данных.
Для этого мы по АПИ заберём готовый набор русского текста из открытого источника:
https://datasets-server.huggingface.co/splits?dataset=Egor-AI/Dataset_of_Russian_thinking
Я пошёл к Chat GPT и попросил его переделать код, чтобы мы могли получить данные из внешнего источника и создать на основе него наш словарь токенов.
Также, после тестовых запусков, я попросил докинуть туда мультипроцессинг, чтобы всё работало быстрее.
!!! Данный код будет работать очень долго! Пока он работает, читайте дальше причину такой медленности, если вы его конечно запустили у себя.
Мы получили такой код:
"""
Параллельная загрузка русского корпуса (HF datasets-server) + обучение BPE.
• I/O-ускорение: ThreadPoolExecutor (DL_WORKERS потоков).
• Порядок строк гарантирован: пишем в файл строго по offset’у.
• Robust: нет поля num_examples → грузим «до пустого ответа».
• Python 3.9, stdlib + requests.
pip install requests
"""
import os, sys, json, time, math, random, threading
from concurrent.futures import ThreadPoolExecutor, as_completed
from typing import Optional, List, Dict, Tuple
from collections import Counter
from multiprocessing import Pool, cpu_count
import requests
# ─────────── настройки ───────────
DATASET, SPLIT, TEXT_KEY = "Egor-AI/Dataset_of_Russian_thinking", "train", "prompt"
ROWS = None # None → весь сплит
BATCH_API = 100 # ≤100 строк в одном запросе
DL_WORKERS = 10 # потоки для скачивания
MERGES = 100_000 # BPE-слияний
END = ""
DATA_FILE = "corpus.txt"
VOCAB_FILE = "vocab.json"
PROC_WORKERS = cpu_count()
# ─────────── надёжный GET-JSON ───────────
def get_json(url: str, tries: int = 10, base: float = 1.5, tout: float = 30):
hdr = {"Accept": "application/json", "User-Agent": "mini-bpe/0.3"}
for attempt in range(1, tries + 1):
r = requests.get(url, timeout=tout, headers=hdr)
if r.ok and "application/json" in r.headers.get("Content-Type", ""):
try: return r.json()
except ValueError: pass
wait = base * 2**(attempt-1) + random.uniform(0, 0.3)
print(f"⚠ {r.status_code} {len(r.text)}B try {attempt}/{tries}", file=sys.stderr)
time.sleep(wait)
raise RuntimeError(f"JSON failed: {url}")
# ─────────── helper: size сплита (если есть) ───────────
def split_size() -> Optional[int]:
meta = get_json(f"https://datasets-server.huggingface.co/splits?dataset={DATASET}")
for s in meta["splits"]:
if s["split"] == SPLIT:
return next((int(s[k]) for k in ("num_examples", "num_rows", "row_count") if k in s), None)
return None
# ─────────── скачиваем один батч ───────────
def fetch_batch(cfg: str, offset: int, length: int) -> Tuple[int, List[str]]:
url = (f"https://datasets-server.huggingface.co/rows"
f"?dataset={DATASET}&config={cfg}&split={SPLIT}"
f"&offset={offset}&length={length}")
rows = get_json(url).get("rows", [])
lines = [str(r["row"][TEXT_KEY]).replace("\n", " ") for r in rows if r["row"][TEXT_KEY]]
return offset, lines
# ─────────── потоковая загрузка корпуса ───────────
def load_corpus(path: str) -> List[str]:
if os.path.isfile(path):
print("⚡ corpus.txt найден")
return [ln.rstrip("\n") for ln in open(path, encoding="utf-8")]
cfg = get_json(f"https://datasets-server.huggingface.co/splits?dataset={DATASET}"
)["splits"][0]["config"]
est_total = ROWS or split_size()
print(f"⇣ скачиваем{' ≈'+str(est_total) if est_total else ''} строк ({DL_WORKERS} потоков)…")
results: Dict[int, List[str]] = {}
next_offset = 0
fetched = 0
t0 = time.time()
lock = threading.Lock()
def submit(off):
return pool.submit(fetch_batch, cfg, off, BATCH_API)
with ThreadPoolExecutor(max_workers=DL_WORKERS) as pool, \
open(path, "w", encoding="utf-8") as fout:
futures = {submit(next_offset): next_offset}
next_offset += BATCH_API
while futures:
done_future = next(as_completed(futures))
off, lines = done_future.result()
futures.pop(done_future)
with lock:
results[off] = lines
# пишем подряд, как только получена следующая часть
write_off = min(results)
while write_off in results:
for ln in results.pop(write_off):
fout.write(ln + "\n")
fetched += BATCH_API
write_off += BATCH_API
# добавляем новый запрос, пока не превысили ROWS (или пока API не пустой)
if ROWS is None or next_offset < ROWS:
futures[submit(next_offset)] = next_offset
next_offset += BATCH_API
if fetched and fetched % 1000 == 0:
speed = fetched / max(time.time()-t0, 1)
print(f" {fetched} строк ({speed:.1f}/s)")
# early-stop, если offset вернул пустой список
if not lines and ROWS is None:
break
print(f"✅ corpus.txt готов ({fetched} строк, {time.time()-t0:.1f}s)")
return [ln.rstrip("\n") for ln in open(path, encoding="utf-8")]
# ─────────── BPE-обучение (как раньше) ───────────
def chunk(lst, n): size = math.ceil(len(lst)/n); return [lst[i*size:(i+1)*size] for i in range(n)]
def pairs_counter(part):
c = Counter()
for w in part:
c.update(zip(w, w[1:]))
return c
def merge_word(tokens, pair, merged):
out,i=[],0
while i < len(tokens):
if i < len(tokens)-1 and (tokens[i],tokens[i+1])==pair:
out.append(merged); i+=2
else:
out.append(tokens[i]); i+=1
return out
def bpe_train(text: str, merges: int, workers: int):
tokd=[list(w)+[END] for w in text.split()]
vocab={t for w in tokd for t in w}
with Pool(workers) as pool:
for step in range(1, merges+1):
pairs=Counter()
for pc in pool.map(pairs_counter, chunk(tokd, workers)):
pairs.update(pc)
if not pairs: break
best,freq=pairs.most_common(1)[0]
m="".join(best); vocab.add(m)
tokd=pool.starmap(merge_word, [(w,best,m) for w in tokd], chunksize=4096)
if step%100==0 or step in (1, merges):
print(f" [{step}/{merges}] +{m} freq={freq}")
return sorted(vocab)
def bpe_encode(text, vocab):
sv=sorted(vocab,key=len,reverse=True); out=[]
for w in text.split():
w+=END; i=0
while i
Из-за ограничения по АПИ, данные я получал около 1,5 часов.
Про само обучение я молчу...
И честно говоря, на полном объёме данных, я так и не дождался обучения, на десятой части данных это заняло около 12 часов.
А за 2 часа на полном объёме у меня выполнился 0,5% от общего объёма.
Чтобы это работало, есть пить не просило, я закинул это в Google Colab и оно у меня там крутилось тихонечко на фоне.
В итоге, я получил ....
['пример', ':', 'мама', 'мыла', 'рам', 'у']
Даже на 1/10 данных вышло хорошо!
По хардкору прошлись, увидели как это работает в самом низу.
Теперь давайте попробуем готовые инструменты для создания токена.
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Русский словарь субслов с «нормальным» BPE (не byte-level).
* корпус берём через Hugging Face `datasets`;
* тренируем BPE обычного вида (символьно-Unicode), поэтому токены читаемы:
▁Пример, ▁мама, ▁мы, ла …
* используем популярную бесплатную библиотеку `tokenizers`
→ быстрая тренировка на CPU, без внешних зависимостей.
pip install datasets tokenizers
"""
from pathlib import Path
from datasets import load_dataset, disable_caching
from tokenizers import Tokenizer, models, trainers, pre_tokenizers, decoders, normalizers
# ──────────────── параметры ────────────────
DATASET = "Egor-AI/Dataset_of_Russian_thinking"
SPLIT = "train"
TEXT_COL = "prompt"
ROWS = None # None → весь сплит
VOCAB_SIZE = 1_000_000
MIN_FREQ = 2 # отбросить совсем редкие
CORPUS_PATH = Path("corpus.txt")
TOK_DIR = Path("ru_bpe") # сохранит vocab.json + merges.txt + tokenizer.json
TOK_DIR.mkdir(exist_ok=True)
# ──────────────── 1. корпус ────────────────
if CORPUS_PATH.exists():
print("⚡ corpus.txt найден — пропускаем загрузку")
else:
print("⇣ скачиваем корпус …")
disable_caching() # не плодим ~/.cache/huggingface
ds = load_dataset(DATASET, split=SPLIT, streaming=True)
with CORPUS_PATH.open("w", encoding="utf-8") as f:
for i, row in enumerate(ds, 1):
txt = str(row.get(TEXT_COL, "")).replace("\n", " ")
if txt:
f.write(txt + "\n")
if ROWS and i >= ROWS:
break
if i % 1_000 == 0:
print(f" {i} строк")
size_mb = CORPUS_PATH.stat().st_size / 1e6
print(f"✅ corpus.txt сохранён ({size_mb:.1f} MB)")
# ──────────────── 2. обучение BPE ────────────────
print("\n⚙️ учим символьный BPE …")
tokenizer = Tokenizer(models.BPE(unk_token="[UNK]"))
tokenizer.normalizer = normalizers.NFKC() # базовая унификация юникода
tokenizer.pre_tokenizer = pre_tokenizers.Whitespace() # режем по пробелу
trainer = trainers.BpeTrainer(
vocab_size=VOCAB_SIZE,
min_frequency=MIN_FREQ,
special_tokens=["[PAD]", "[UNK]", "[CLS]", "[SEP]", "[MASK]"]
)
tokenizer.train([str(CORPUS_PATH)], trainer)
tokenizer.decoder = decoders.BPEDecoder()
tokenizer.model.save(str(TOK_DIR)) # сохранит merges & vocab
tokenizer.save(str(TOK_DIR / "tokenizer.json"))
print(f"✅ словарь {VOCAB_SIZE} токенов → {TOK_DIR}")
# ──────────────── 3. тест ────────────────
sample = "Пример: мама мыла раму"
enc = tokenizer.encode(sample)
print("\n🧪 токены:", enc.tokens)
print("🧪 восстановленная строка:", tokenizer.decode(enc.ids))
Заметим, что скачивание будет идти так же долго, если файл не был скачан прошлым скриптом.
НО!
Само обучение пролетело за какие-то 2 минуты!
Как же так???
Я был в шоке и подумал, что это ошибка или у меня подгрузился уже готовый токинизатор или это не мои данные, на которых я обучал, а что-то уже заранее готовое.
Но нет, это токинезатор, который я получил только на своих данных.
И как же так это вышло?
А всё оказывается просто, Python - очень медленный.
Дело вовсе не в «магии» библиотек, а в том, на чём и как они написаны.
Если без сложных слов и терминов, то Python это высокоуровневый и интерпретируемый язык программирования и каждый элемент универсален но при этом тяжёлый. А когда нам надо создать миллионы или миллиарды элементов и сделать с ними ещё больше операций, то это очень сильно замедляет само себя.
А сторонняя библиотека работает на низком уровне и имеет оптимальные алгоритмы, которые так кратно ускоряют работу!
Суммарно получается ускорение в моём случае в тысячи раз!
Я знал, что Python медленный, но впервые увидел настолько колоссальный разрыв на практическом примере.
Ну как-то и всё.
Теперь у нас есть свой словарь токенов и мы можем через него разбивать наш текст на токены.
И вроде бы следующий этап Векторы, но их мы получаем в процессе обучения нейросетей, так что разберём в другой раз.
Итоги
Создать свой словарь токенов совершенно не сложно, и для небольшого объёма данных ещё и достаточно быстро.
Но надо понимать, если бы собрали реальный датасет для обучения, не на миллионе символов, а на триллиардах или более, то собирался бы такой словарь гораздо дольше!
Но это реально, и мы смогли даже пощупать основы.
Следующий этап, это создание собственной нейронки, но этим мы займёмся в другой статье!
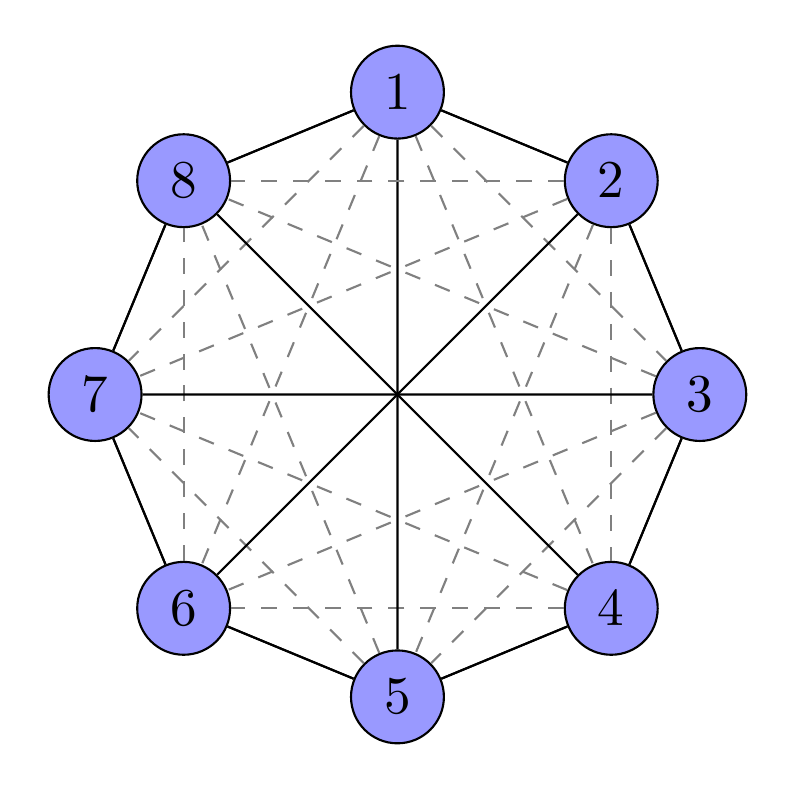
Все кружки находятся равномерно друг от друга.
И чем больше измерений, тем больше возможностей по расположению и близости объектов друг к другу.